Scalable High Productivity Systems
Large-scale biometric projects may have specific system performance requirements. The MegaMatcher Accelerator family of products is intended for large-scale AFIS / ABIS projects and offers different matching engines and editions for high performance during large number of requests.
MegaMatcher Accelerator provides easy system scalability and allows to start a biometric system from a single unit at the beginning, with further scaling up together with project capacity and speed requirements by expanding the system into cluster and/or upgrading the units using engines with higher capabilities.
MegaMatcher Accelerator is designed for using together with other components of MegaMatcher SDK, which provide biometric data capture and template extraction. These system architectures are usually used for specific projects:
- Template creation on client-side and matching on server-side – recommended for AFIS, border control, various ID issuing systems, such as passports, ID cards, voter registration.
- Template creation and matching on server side – recommended for online banking, government e-services and other mass scale systems, in which requests can be submitted by any device or computer.
- Deduplication after all users data collected – recommended for ID issuing systems, which have previously collected biometric data, such as voter or population registry cleaning.
A combination of the mentioned architectures and components can be also used within a large-scale biometric system to reach optimal performance and/or availability.
MegaMatcher Accelerator software licenses are available for new and existing MegaMatcher Extended SDK customers.
MegaMatcher Automated Biometric Identification System, an integrated multi-biometric solution for national-scale identification projects, can be also considered. The solution can be customized by Neurotechnology for specific project needs.
See Product Advisor to find out what Neurotechnology products and system architectures will best suit your project requirements.
Template creation on client-side and matching on server-side
This is the most often used architecture for AFIS / ABIS, border control, various ID issuing systems, such as passports, ID cards or voter registration. It is suitable for various systems, ranging from small LAN-based systems to national-scale projects. The chart below shows the key components need for this architecture.
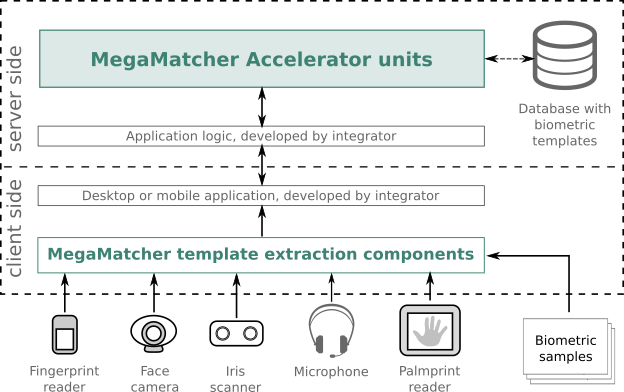
The ready-to-use MegaMatcher Accelerator 2025.1 units are deployed on the server-side and include biometric engines for matching fingerprint, palmprint, face, iris and voiceprint templates, which can be easily scaled up at any time for higher performance based on the project requirements.
MegaMatcher template extraction components are used by integrators to develop client-side desktop or mobile applications. The components include all necessary functionality and performance for biometric data capture and template extraction for sending them to the server-side. The applications deployment needs only additional licenses for the corresponding components for each computer or device running the application.
Template creation and matching on server side
This architecture is designed to be used for biometric systems, which need to process requests from a very large number of clients in scenarios like online banking or government e-services, as well as other mass scale systems with very large number of users. The chart below shows the key components needed for this architecture.
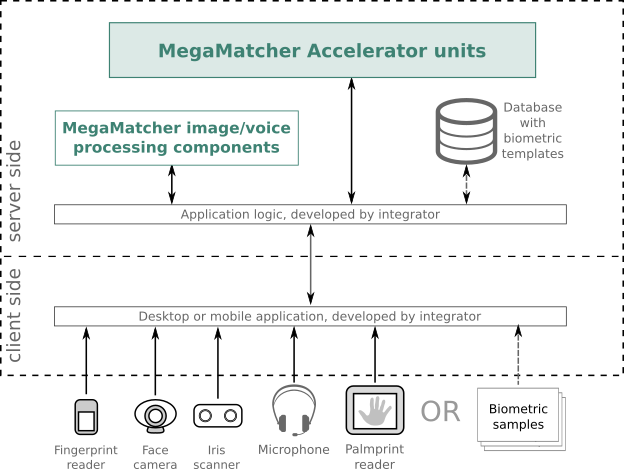
The ready-to-use MegaMatcher Accelerator 2025.1 units are deployed on the server-side and include biometric engines for matching fingerprint, palmprint, face, iris and voiceprint templates, which can be easily scaled up at any time for higher performance based on the project requirements.
MegaMatcher template extraction components are deployed on the server-side of the biometric system. The integrators need to develop application logic, which will operate with the template extraction components.
MegaMatcher biometric data capture components provide necessary functionality for client-side applications, which acquire biometric images from scanners or cameras and send them to the server-side for further template extraction.
Applications deployment needs only additional licenses for the corresponding components for each computer or device running the application.
Integrators can also implement image capture by themselves and send images to the server-side part of the system.
In this case client-side applications deployment does not need any licenses for Neurotechnology components.
Deduplication after all users data collected
This architecture is intended for large-scale projects, like voter registration or population registry cleaning, when users' biometric data collection is done in two steps. First, the biometric data is captured on multiple sites, which are not connected to the central database. Later, the biometric data from all sites is submitted to the central database and checked for duplicates. The chart below shows the key components need for this architecture.
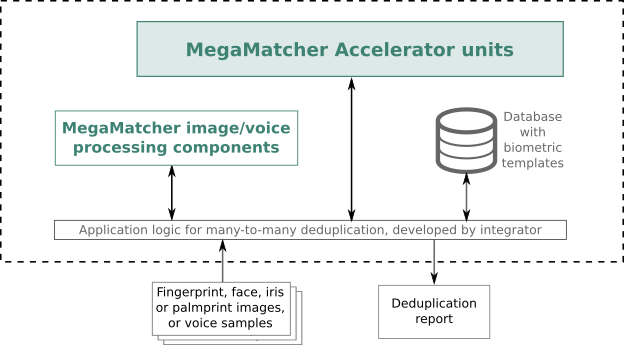
The ready-to-use MegaMatcher Accelerator 2025.1 units are deployed on the server-side and include biometric engines for matching fingerprint, palmprint, face, iris and voiceprint templates, which can be easily scaled up at any time for higher performance based on the project requirements. Integrators will need to develop simple application logic for sending the biometric templates for many-to-many deduplication and generating the duplicates search report. Note, that database deduplication task requires a lot of computational resources, as it needs to compare every biometric template with every other biometric template in a database.
MegaMatcher template extraction components may need to be deployed on the server-side, as usually the biometric data is captured as fingerprint, palmprint, face or iris images, or voice records, which need to be processed into biometric templates. The integrators need to develop application logic, which will operate with the template extraction components.
Product Advisor can provide an estimation of possible components and their quantities based on the actual duplicates search project requirements.
You may also consider the MegaMatcher ABIS Cloud Service, which provides results for a reasonable price without the need to develop a solution.
Scalable server-side matching with MegaMatcher Accelerator
MegaMatcher Accelerator 2025.1 is a solution for large-scale AFIS and multi-biometric projects, which is available as Development Edition, Standard, Extended and Extreme versions. A system based on MegaMatcher Accelerator with a single unit can be scaled up by adding more units to create a cluster and/or upgrading to a more powerful version of MegaMatcher Accelerator. The MegaMatcher Accelerator includes necessary software to enable system scalability, high availability and fault tolerance.
MegaMatcher Accelerator 2025.1 software is provided with MegaMatcher 2025.1 Extended SDK.
The table below compares different versions of MegaMatcher Accelerator 2025.1 solution.
| Database capacity | Matching speed | ||
| Cluster of MegaMatcher Accelerator 2025.1 Development Edition with N units | Fingerprints | N × 4,000,000 fingerprints |
N × 1,000,000 fingerprints per second |
| Faces | N × 1,000,000 faces |
N × 1,000,000 faces per second |
|
| Irises | N × 5,000,000 irises |
N × 1,000,000 irises per second |
|
| Voiceprints | N × 1,000,000 voiceprints |
N × 200,000 voiceprints per second |
|
| Palmprints | N ×800,000 palmprints |
N × 20,000 palmprints per second |
|
| Cluster of MegaMatcher Accelerator 2025.1 Standard with N units | Fingerprints | N × 4,000,000 fingerprints |
N × 35,000,000 fingerprints per second |
| Faces | N × 1,000,000 faces |
N × 35,000,000 faces per second |
|
| Irises | N × 5,000,000 irises |
N × 70,000,000 irises per second |
|
| Voiceprints | N × 1,000,000 voiceprints |
N × 10,000,000 voiceprints per second |
|
| Palmprints | N × 800,000 palmprints |
N × 600,000 palmprints per second |
|
| Cluster of MegaMatcher Accelerator 2025.1 Extended with N units | Fingerprints | N × 40,000,000 fingerprints |
N × 100,000,000 fingerprints per second |
| Faces | N × 10,000,000 faces |
N × 100,000,000 faces per second |
|
| Irises | N × 50,000,000 irises |
N × 200,000,000 irises per second |
|
| Voiceprints | N × 10,000,000 voiceprints |
N × 30,000,000 voiceprints per second |
|
| Palmprints | N × 8,000,000 palmprints |
N × 2,000,000 palmprints per second |
|
| Cluster of MegaMatcher Accelerator 2025.1 Extreme with N units | Fingerprints | N × 160,000,000 fingerprints |
N × 1,200,000,000 fingerprints per second |
| Faces | N × 40,000,000 faces |
N × 1,200,000,000 faces per second |
|
| Irises | N × 200,000,000 irises |
N × 1,200,000,000 irises per second |
|
| Voiceprints | Voiceprint engine is not available in MegaMatcher Accelerator Extreme Edition |
||
| Palmprints | Palmprint engine is not available in MegaMatcher Accelerator Extreme Edition |
||
Recommendations:
- MegaMatcher Accelerator Development Edition has no limitations on cluster size, but in general it makes no sense to run more than 3 nodes in the cluster, as the whole system will cost like one MegaMatcher Accelerator Standard unit while providing lower performance.
- MegaMatcher Accelerator Standard has no limitations on cluster size, but in general it makes no sense to run more than 2 nodes in the cluster, as the whole system will cost like one MegaMatcher Accelerator Extended unit while providing lower performance and capacity.
- MegaMatcher Accelerator Extended has no limitations on cluster size, but in general it makes no sense to run more than 4 nodes in the cluster, as the whole system will cost like one MegaMatcher Accelerator Extreme unit while providing lower performance and capacity.
- The matching speeds are provided for single-biometrics engines. If a template in a database contains multi-biometric entries, like fingerprint and face records belonging to the same person, the matching components will match proportionally lower number of persons' biometric database entries per second. See the Product Advisor for the estimated matching components based on the contents of biometric template and performance requirements.
- MegaMatcher Accelerator unit(s) can be used for fast candidate selection using irises, faces or several fingerprints with further results validation using slower fingerprint, face, iris and voiceprint matching engines which are also included with MegaMatcher Accelerator.
- Smaller systems, which need to match up to 200,000 fingerprints, faces or irises per second, can be based on the Matching Server which is available in the MegaMatcher SDK.
Also, two or more MegaMatcher Accelerator based clusters can be connected together for a high availability system.
MegaMatcher Accelerator cluster software
MegaMatcher Accelerator includes cluster software, thus multiple MegaMatcher Accelerator 2025.1 units (cluster nodes) can be connected via network to a cluster. A cluster of MegaMatcher Accelerators may be scaled up at anytime, meeting changing project requirements such as an increase in number of users or request environment. The cluster software provides these advanced capabilities:
-
Horizontal scalability – achieved by adding new MegaMatcher Accelerator nodes to a cluster.
Because each unit operates on a portion of the database, an increase in the number of MegaMatcher Accelerator units results in faster matching and a higher number of processed requests.
For example, there is a database with the biometric data for 15 million people (4 fingerprints for each user, 60 million fingerprints in total). The number of required MegaMatcher Accelerator units would be calculated in this way:- The whole database should fit into the memory of the MegaMatcher Accelerator units. A single MegaMatcher Accelerator 2025.1 Extended unit stores 40 million fingerprints, therefore, 2 units would be required to store the 60 million fingerprint database.
- The response time for an identification request should satisfy project requirements. A single MegaMatcher Accelerator 2025.1 Extended unit matches 27 million fingerprint templates per second in 4-to-many mode If the project requires receiving an an answer to an identification request in 1 second, therefore, two units will satisfy the project requirements for response time.
- The peak hour request quantity should satisfy project requirements. For example, the project expects that there may be up to 15,000 identification requests per hour. A single MegaMatcher Accelerator 2025.1 Extended unit matches 27 million fingerprint templates per second in 4-to-many mode, it will therefore be able to process 6,480 requests per hour with the sample 15 million template database. A cluster of 3 MegaMatcher Accelerator 2025.1 Extended units will be required to process the expected number of identification requests in this case.
- Vertical scalability – usually achieved by upgrading to a more powerful edition of MegaMatcher Accelerator. For example, a single MegaMatcher Accelerator Extended unit provides almost three times faster biometric matching and can store ten times more biometric templates compared to a single MegaMatcher Accelerator Standard unit.
- Fault tolerance – a cluster of MegaMatcher Accelerators can restore its operation after one or more of the nodes abnormally leaves the cluster for any reason, like hardware or network failure, software issue etc. The cluster software automatically detects the failure events and redistributes the data from the failed nodes between the active nodes to keep the whole database available for identification requests. Naturally, this functionality requires to have larger number of nodes than the minimum needed for the specified performance and/or capacity, so there are some reserve for replacing the failed nodes.
- High availability – two clusters of MegaMatcher Accelerators may be run in parallel, keeping the data synchronized between the clusters. This configuration provides twice the performance while both clusters operate normally. If one cluster becomes unavailable, the other will continue operation and provide the standard level of performance.
- Peer-to-peer architecture – the cluster nodes automatically distribute biometric database and requests from clients between themselves. This architecture means that there are no master node in the cluster, therefore there are no issues with single point of failure or bottleneck.
- Nonstop operation – there are no downtime while new nodes are being added to the cluster or one of the nodes disappears. The normal system operation is not interrupted.